PRESS RELEASES

New hardware architecture provides an edge in AI computationResearch news

Edge-computing AI breakthrough achieved with hafnium-oxide ferroelectrics
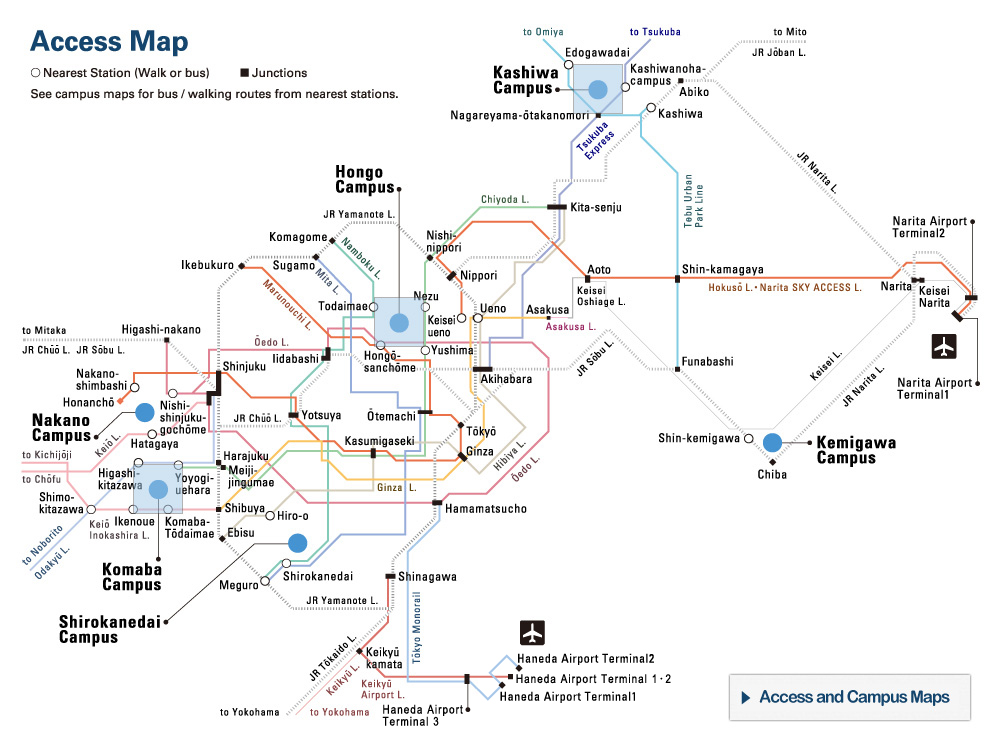
The research findings demonstrated that reservoir computing can be implemented with ferroelectric gate transistors (FeFETs) in a computing-in-memory fashion. ©2022 Shinichi Takagi, The University of Tokyo
As applications of artificial intelligence spread, more computation has to occur — and more efficiently with lower energy consumption — on local devices instead of geographically distant data centers in order to overcome frustrating delays in response. A group of University of Tokyo engineers have for the first time tested the use of hafnium-oxide ferroelectric materials for physical reservoir computing — a type of neural network that maps data onto physical systems and may achieve precisely such an advance — on a speech recognition application.
They described their results in a paper presented at the hybrid 2022 IEEE Symposium on VLSI Technology & Circuits, held in Honolulu, Hawaii, June 12-17.
Development of artificial intelligence (AI) technology and its myriad applications have exploded in recent years, but a major barrier to its further deployment comes from colossal computation cost and energy consumption, especially where such computation is carried out by software whose physical location lies in data centers a considerable distance from the user.

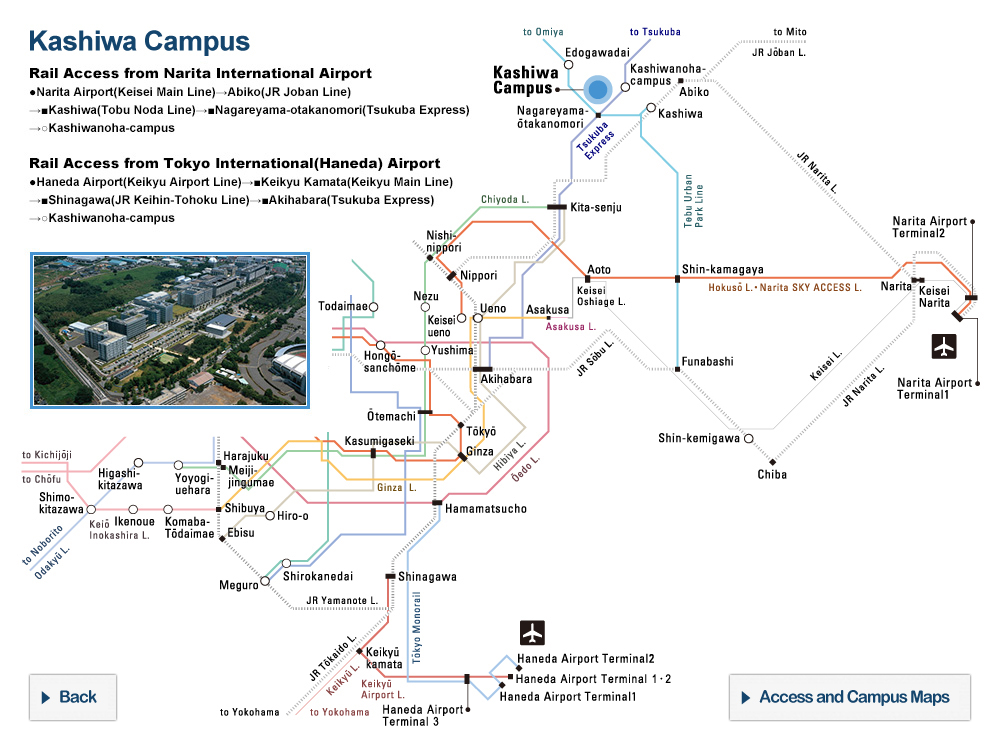
Atomic layer deposition (ALD) machine for deposition of HfZrO2 ferroelectric films
This machine is used to deposit a thin film of hafnium oxide-based ferroelectric materials to produce ferroelectric gate transistors (FeFETs) used in a new physical reservoir computing architecture devised by University of Tokyo researchers. ©2022 Kasidit Toprasertpong, The University of Tokyo
Even with data traveling through networks at the speed of light, there can be delays of split seconds or longer between a user’s request and the delivery of an application’s response. This is due to the great distances as photons travel thousands of miles from user to data center — sometimes half a globe away — and then back. For consumer applications from video games to voice assistants, this small delay can be frustrating, but for mission-critical applications in government, from health care to defense, such delays — known as latency — can cost lives.
Computer scientists and engineers focus on two lines of attack with respect to overcoming this challenge: shifting at least some of the computation required from software to hardware, and from the centralized data centers, or cloud, back to a local device.
The first strategy is necessary because it makes no sense to only attempt efficiency gains in the programs one is running and not also in the machines that they run on. The second strategy, known as edge computing, reduces latency as there is simply less distance for data to travel. When your smartphone performs the computations involved in a biometric check (and not the data center some distance away), this is an example of edge computing’s dispersion of computation from the cloud back to the device.
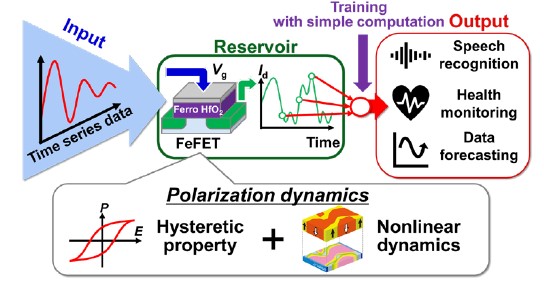
Lately, physical reservoir computing (PRC) — in which efficiency gains are achieved in the local device’s hardware — has attracted a great deal of attention from engineering researchers for its ability to advance both these lines of attack. PRC is an outgrowth of the development of recurrent neural networks (RNNs), a type of machine learning that is well suited to processing of data over time (temporal data) rather than that of static data. This is because RNNs take into account information from previous inputs to consider a current input (hence “recurrent”), and from that, the output. Because of this ability to deal with temporal data, RNNs are suitable for applications whose conclusions (or inferences) are sensitive to the data’s sequence or time-based context, such as speech recognition, natural language processing or language translation, and used by applications such as Google Translate or Siri.
In physical reservoir computing, the input data are mapped onto patterns in some physical system, or reservoir (such as the patterns in the structure of a magnetic material, a system of photons, or a mechanical device), that enjoys a higher dimensional space than the input. (A piece of paper is a space that has one dimension higher than a piece of string, and a box has yet one more dimension than the piece of paper.) Then, a pattern analysis is performed on spatio-temporal patterns on the final readout “layer” to understand the state of the reservoir. Because the AI is not trained on the recurrent connections within the reservoir, but only on the readout, simpler learning algorithms are achievable, dramatically reducing the computation required, enabling high-speed learning and lowering the energy consumption.

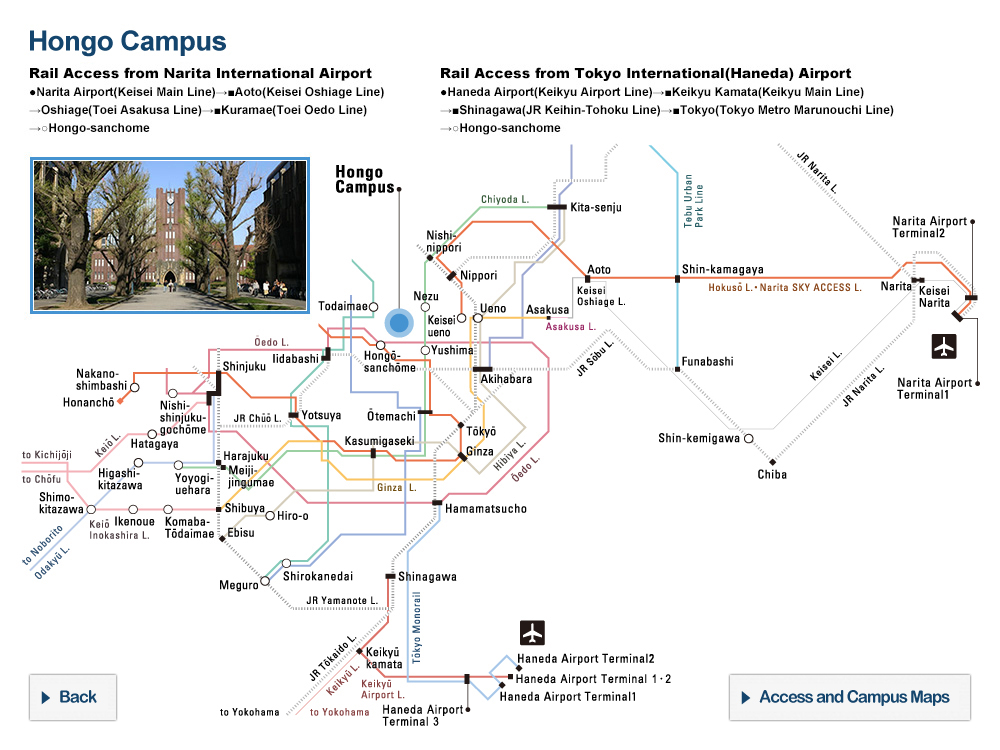
Electrical measurement system of FeFET reservoir
The system is used to measure the performance of a new hardware architecture making use of hafnium-oxide ferroelectrics for the emerging concept of physical reservoir computing. ©2022 Kasidit Toprasertpong, The University of Tokyo
The University of Tokyo engineers had earlier devised a new PRC architecture that uses ferroelectric gate transistors (FeFETs) made of hafnium oxide-based ferroelectric materials. Most people are familiar with ferromagnetism, in which an iron magnet is permanently magnetized in a particular polar direction (one part of the magnet becomes its “north” and the other end its “south”). Ferroelectricity involves an analogous phenomenon wherein certain materials — in this case hafnium oxide and zirconium oxide — that experience an electric polarization (a shift of positive and negative electric charge) that can subsequently be reversed by the application of an external electric field. This switchable polarization can thus store memory like any transistor. In 2020, the researchers had also demonstrated that a basic operation of reservoir computing was possible using these materials.
“These materials are already commonly used in semiconductor integrated circuit manufacturing processes,” said Shinichi Takagi, a co-author of the paper and professor with the Department of Electrical Engineering and Information Systems at the University of Tokyo. “This means that FeFET reservoirs are expected to be integrated with large-scale semiconductor integrated circuit fabrication with little difficulty compared to some more novel material.”
While hafnium oxide-based ferroelectric materials had enjoyed a great deal of attention in the semiconductor industry because of their ferroelectricity, what sort of applications FeFET-based physical reservoir computing was suitable for and how well it performed in actual applications had yet to be investigated.

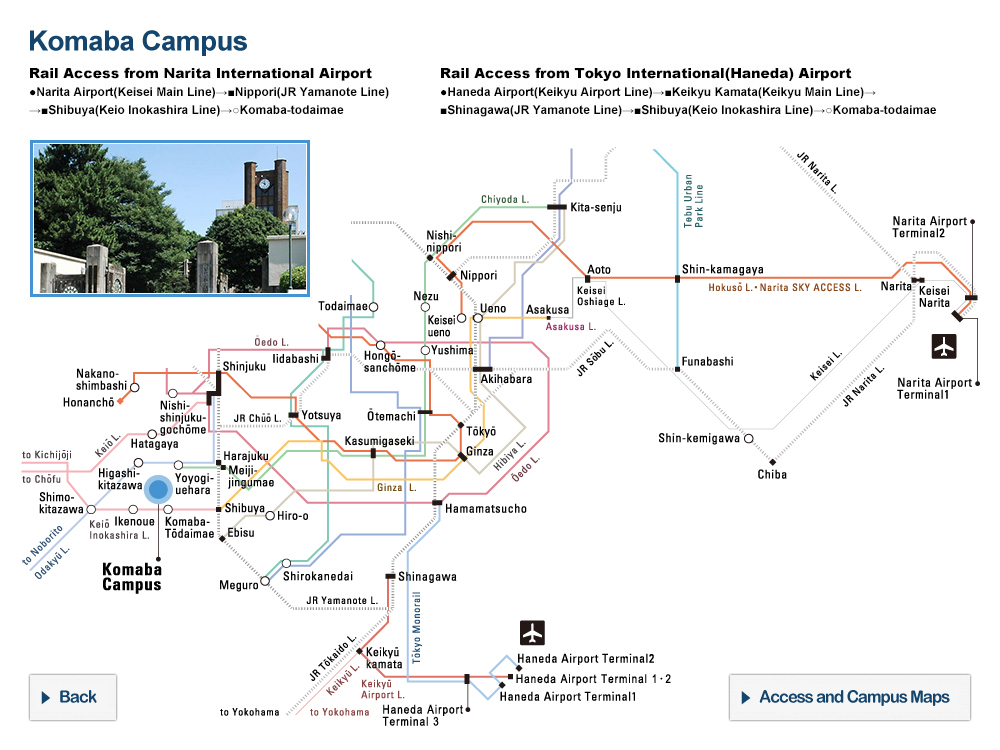
Patterns of FeFETs used in reservoir computing
The patterns of ferroelectric gate transistors (FeFETs) shown here are used in a novel physical reservoir computing architecture devised by a team of University of Tokyo researchers. ©2022 Kasidit Toprasertpong, The University of Tokyo
Having proven their PRC architecture feasible two years ago, the researchers then tested it on a speech recognition application. They found it to be 95.9% accurate for speech recognition of the numbers zero to nine. This proved for the first time the usability of the technology in a real-world application.
The researchers now want to see if they can increase the computing performance of their FeFET reservoirs, as well as testing them on other applications.
Ultimately, the researchers hope to demonstrate that an AI chip with the hafnium oxide-based ferroelectric PRC architecture can achieve a high level of performance in terms of extremely low power consumption and real-time processing compared to conventional AI calculation methods and hardware.
Papers
E. Nako, K. Toprasertpong, R. Nakane, M. Takenaka, and S. Takagi, "Experimental Demonstration of Novel Scheme of HZO/Si FeFET Reservoir Computing with Parallel Data Processing for Speech Recognition," 2022 IEEE Symposium on VLSI Technology & Circuits: June 12, 2022