Netflixはなぜ好みの映画がわかる?→武田朗子|素朴な疑問vs東大

「なぜ?」から始まる学術入門
言われてみれば気になる21の質問をリストアップし、その分野に詳しそうなUTokyo教授陣に学問の視点から答えてもらいました。知った気でいるけどいざ聞かれると答えにくい身近な疑問を足がかりに、研究の世界を覗いてみませんか。
Q.6 Netflixはなぜ好みの映画がわかるの?
ネトフリに限らずサブスク型の動画配信サービスがいつも自分の好きな映画をリコメンドしてきて驚きます。どうやってるの? 回答者/武田朗子
回答者/武田朗子現実の問題を数理モデルとして記述し解く
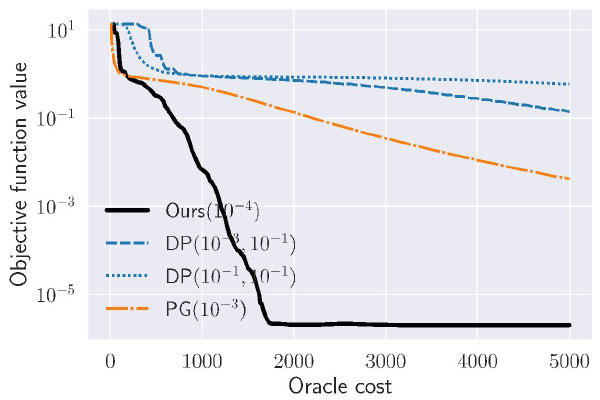
私は数理最適化に関する汎用的なアルゴリズム(計算手順)を研究しています。簡単にいえば、目的を達成するための最善の手を見つけるのが最適化。もともとは戦争の際に限られた兵器や兵士を使って敵に最大のダメージを与える方法を考えることから出てきた分野です。建築構造、コンピュータ将棋、避難場所の設定、在庫管理、クレーン制御、学生の研究室配属などなど、世の中で解決したい問題を捨象し、線形関数や二次関数などのふさわしい関数を用意して数理モデルとして記述します。それをいかに速く解くかを考えるのが私の研究。速く解くにはなるべく計算量の少ないアルゴリズムを作る必要があります。
最適化問題は離散最適化と連続最適化に大別されます。たとえば、本郷三丁目駅から駒場東大前駅に最短時間で行く経路を答えよという問題は離散最適化の対象。一方、手書き文字をコンピュータに機械学習させて自動認識できるかという問題は連続最適化です。両者は解き方が違い、解くのに使う道具が違います。
ネットフリックスの推薦システムは連続最適化の対象になります。ユーザーごとの映画レイティング情報があるとします(MovieLensというデータセットがよく知られています)。似たレイティングをする人は好みが似ていると考え、まだ観ていない映画Aがある場合に、好みが近い人がAにつけた評価をあてはめて推薦する。これがリコメンドの仕組みです。
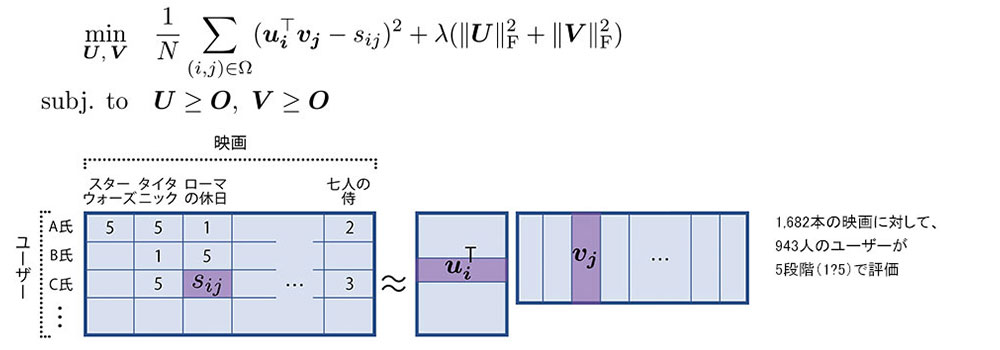
専門的な言い方をすると、非負値行列因子分解(Non-negative Matrix Factorization)を用いた欠損値補完問題になります(非負値行列は全て0以上の値が入る行列の意)。ユーザーごと、映画ごとのレイティング数値が入った行列を2つの小さな行列に分離させて掛け算の形で表し、最適化問題を解くことにより(下の数式の)UとVが決まれば、抜けている部分の数値を表示できるようになります。SF好き、黒澤好き、恋愛好き……のような潜在因子(嗜好パターン)があるとして、それがユーザーと映画の両方に強い関連性を持っていれば高評価だと判断し、まだ観ていない映画も好きだと推測できます。ただし潜在因子が何であるかを決める必要はなく、データだけあればよいことになります。
多くの人が楽しんでいる動画配信サービスの推薦システムは、このような数理最適化の研究成果が支えているのです。